Grammar
Tenses
Present

Present Simple
Present Continuous
Present Perfect
Present Perfect Continuous
Past
Past Simple
Past Continuous
Past Perfect
Past Perfect Continuous
Future
Future Simple
Future Continuous
Future Perfect
Future Perfect Continuous
Parts Of Speech
Nouns
Countable and uncountable nouns
Verbal nouns
Singular and Plural nouns
Proper nouns
Nouns gender
Nouns definition
Concrete nouns
Abstract nouns
Common nouns
Collective nouns
Definition Of Nouns
Animate and Inanimate nouns
Nouns
Verbs
Stative and dynamic verbs
Finite and nonfinite verbs
To be verbs
Transitive and intransitive verbs
Auxiliary verbs
Modal verbs
Regular and irregular verbs
Action verbs
Verbs
Adverbs
Relative adverbs
Interrogative adverbs
Adverbs of time
Adverbs of place
Adverbs of reason
Adverbs of quantity
Adverbs of manner
Adverbs of frequency
Adverbs of affirmation
Adverbs
Adjectives
Quantitative adjective
Proper adjective
Possessive adjective
Numeral adjective
Interrogative adjective
Distributive adjective
Descriptive adjective
Demonstrative adjective
Pronouns
Subject pronoun
Relative pronoun
Reflexive pronoun
Reciprocal pronoun
Possessive pronoun
Personal pronoun
Interrogative pronoun
Indefinite pronoun
Emphatic pronoun
Distributive pronoun
Demonstrative pronoun
Pronouns
Pre Position
Preposition by function
Time preposition
Reason preposition
Possession preposition
Place preposition
Phrases preposition
Origin preposition
Measure preposition
Direction preposition
Contrast preposition
Agent preposition
Preposition by construction
Simple preposition
Phrase preposition
Double preposition
Compound preposition
prepositions
Conjunctions
Subordinating conjunction
Correlative conjunction
Coordinating conjunction
Conjunctive adverbs
conjunctions
Interjections
Express calling interjection
Phrases
Sentences
Clauses
Part of Speech
Grammar Rules
Passive and Active
Preference
Requests and offers
wishes
Be used to
Some and any
Could have done
Describing people
Giving advices
Possession
Comparative and superlative
Giving Reason
Making Suggestions
Apologizing
Forming questions
Since and for
Directions
Obligation
Adverbials
invitation
Articles
Imaginary condition
Zero conditional
First conditional
Second conditional
Third conditional
Reported speech
Demonstratives
Determiners
Direct and Indirect speech
Linguistics
Phonetics
Phonology
Linguistics fields
Syntax
Morphology
Semantics
pragmatics
History
Writing
Grammar
Phonetics and Phonology
Semiotics
Reading Comprehension
Elementary
Intermediate
Advanced
Teaching Methods
Teaching Strategies
Assessment


Taking stock
 المؤلف:
David Odden
المؤلف:
David Odden
 المصدر:
Introducing Phonology
المصدر:
Introducing Phonology
 الجزء والصفحة:
182-6
الجزء والصفحة:
182-6
 5-4-2022
5-4-2022
 1292
1292




+
-
20
Taking stock
We should review the analysis to be sure there are no loose ends. We have six rules – j-deletion, vowel deletion, r-insertion, consonant voicing, velar vocalization, and labial nasalization – which, given our assumptions regarding roots and suffixes, account for most of the forms in the data set. It is important to recheck the full data set against our rules, to be certain that our analysis does handle all of the data. A few forms remain which we cannot fully explain.
The forms which we have not yet explained are the following. First, we have not explained the variation in the root-final consonant seen in the verb meaning ‘win’ (kats -u, kat-anai-anai, kat ʃ -itai, kat-ta, kat-o:). Second, we have not accounted for the variation between s and ʃ in the verb ‘shear,’ nor have we explained the presence of the vowel [i] in the past tense of this verb. Finally, in the verb ‘buy’ we have not explained the presence of [w] in the negative, the appearance of a second [t] in the past-tense form, and why in the inchoative form [kao:] the suffix consonant j deletes.
Correcting the final consonant. The first problem to tackle is the variation in the final consonant of the verb ‘win.’ Looking at the correlation between the phonetic realization of the consonant and the following segment, we see that [ts ] appears before [u], [t ʃ ] appears before [i], and [t] appears elsewhere. It was a mistake to assume that the underlying form of this root contains the consonant /ts /; instead, we will assume that the underlying consonant is /t/ (so nothing more needs to be said about the surface forms kat-anai, kat-ta, and kat-o:). Looking more generally at the distribution of [tʃ ] and [ts ] in the data, [t ʃ ] only appears before [i], and [ts ] only appears before [u], allowing us to posit the following rules.
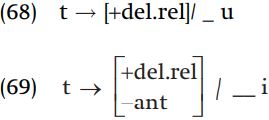
Moving to the word for ‘lend,’ we find a related problem that /s/ appears as [ʃ] before [i]. This is reminiscent of the process which we assumed turning t into tʃ before i. In fact, we can decompose the process  into two more basic steps: /t/ becomes an affricate before [i], and s and ts become alveopalatal [ʃ] and [tʃ ] before the vowel [i].
into two more basic steps: /t/ becomes an affricate before [i], and s and ts become alveopalatal [ʃ] and [tʃ ] before the vowel [i].
i-epenthesis. All that remains to be explained about the word for ‘lend’ is why [i] appears in the past tense, i.e. why does /kasta/ become kasita (whence [kaʃita])? This is simple: we see that [st] does not exist in the language, and no assimilations turn it into an existing cluster, so [i] is inserted to separate these two consonants.
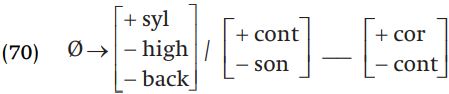
r-assimilation and final w. Turning now to the form [katta] ‘shear (past)’ from /kar-ta/, a simple assimilation is needed to explain this form:
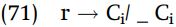
The last remaining problems are in the verb ‘buy,’ where we must explain the extra [t] in [katta], the presence of [w] in [kawanai], and the loss of /j/ in the inchoative form [kao:]. We might explain the form [kawanai] by a rule of w-insertion inserting w between two occurrences of the vowel [a]; more puzzling is the form [katta], which we presume derives from /ka-ta/. It would be very unusual for a consonant to spontaneously double between vowels. Since there are so many problems associated with this one root, perhaps the problem lies in our assumptions about the underlying form of this root. Perhaps the w in [kawanai] is part of the root itself. What would be the benefit of assuming that this root is really /kaw/? First, it explains the presence of w in [kawanai]. Second, it provides a basis for the extra [t] in [katta]: /w/ assimilates to following [t]. Such an assimilation is implicit in our analysis, namely rule (71) assimilating /r/ to /t/. We can generalize this rule to applying to both /r/ and /w/, which are oral sonorants. Finally, positing underlying /kaw/ helps to resolve the mystery of why /j/ deletes in the inchoative form [kao:], when otherwise /j/ only deletes when it is preceded by a consonant. If we start with /ka-jo:/ there is no reason for /j/ to delete, but if we start with /kaw-jo:/, /j/ is underlyingly preceded by a consonant /w/, which causes deletion of j, and then /w/ itself is deleted.
The cost of this analysis – a small cost – is that we must explain why [w] does not appear more widely in the root, specifically, why we do not find surface [w] in ka-u, ka-itai, and ka-o:. The answer lies in the context where [w] appears: [w] only appears before a low vowel, suggesting the following rule.
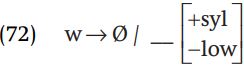
At this point, we have a complete analysis of the data. The rules (in shorthand versions) and underlying forms are recapitulated below.

Progress by hypothesis forming and testing. Three important points have emerged as our analysis developed. First, analysis proceeds step-by-step, by forming specific hypotheses which we then check against the data, revising those hypotheses should they prove to be wrong. Second, it is vital to consider more than one hypothesis: if we had only pursued the first hypothesis that the roots /ne/, /mi/, /kar/, and /kaw/ were really underlying /ner/, /mir/, /kar/, and /ka/, we would never have been able to make sense of the data. The most important skill that you can bring to the task of problem solving is the ability to create and evaluate competing hypotheses intended to explain some fact. Finally, it is particularly important to remember that assumptions about underlying representations go hand-in-hand with the phonological rules which you postulate for a language. When you check your solution, the problem may not be that your rules are wrong, but that your underlying forms are wrong. By continuously reviewing the analysis, and making sure that the rules work and your assumptions about underlying forms are consistent, you should arrive at the stage that no further improvements to the analysis are possible, given the data available to you.
It might occur to you that there are aspects of the underlying representation which could still be questioned. Consider the present-tense form, which we assumed was /u/. An alternative may be considered: the suffix might be /ru/. The presence of underlying /r/ in this suffix is made plausible by the fact that r actually appears in the forms miru, neru. We assumed that r is epenthetic, but perhaps it is part of the present suffix. That would allow us to eliminate the rule of r-epenthesis which is needed only to account for [neru] and [miru]. At the same time, we can also simplify the rule of vowel deletion, by removing the restriction that only nonround vowels delete after [e] and [i]: we made that assumption only because /ne-u/ and /mi-u/ apparently did not undergo the process of vowel deletion.
Any change in assumed underlying forms requires a reconsideration of those parts of the analysis relevant to that morpheme. We would then assume the underlying forms /ʃin-ru/, /jom-ru/, /kat-ru/, and so on, with the root-final consonant being followed by /r/. This /r/ must be deleted: but notice that we already have a rule which, stated in a more general form, would delete this /r/, namely the rule deleting /j/ after a consonant.
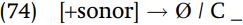
If we generalize that rule to apply to any sonorant consonant after a consonant, we eliminate the rule of r-insertion, and generalize the rules j-deletion and vowel deletion, which results in a better analysis.
 0
0
 0
0
لا توجد تعليقات بعد
ما رأيك بالمقال : كن أول من يعلق على هذا المحتوى
 الاكثر قراءة في Phonology
الاكثر قراءة في Phonology
 اخر الاخبار
اخر الاخبار
اخبار العتبة العباسية المقدسة

الآخبار الصحية


مواضيع ذات صلة
 قسم الشؤون الفكرية يصدر كتاباً يوثق تاريخ السدانة في العتبة العباسية المقدسة
قسم الشؤون الفكرية يصدر كتاباً يوثق تاريخ السدانة في العتبة العباسية المقدسة "المهمة".. إصدار قصصي يوثّق القصص الفائزة في مسابقة فتوى الدفاع المقدسة للقصة القصيرة
"المهمة".. إصدار قصصي يوثّق القصص الفائزة في مسابقة فتوى الدفاع المقدسة للقصة القصيرة (نوافذ).. إصدار أدبي يوثق القصص الفائزة في مسابقة الإمام العسكري (عليه السلام)
(نوافذ).. إصدار أدبي يوثق القصص الفائزة في مسابقة الإمام العسكري (عليه السلام)