النبات

مواضيع عامة في علم النبات
الجذور - السيقان - الأوراق
النباتات الوعائية واللاوعائية
البذور (مغطاة البذور - عاريات البذور)
الطحالب
النباتات الطبية
الحيوان
مواضيع عامة في علم الحيوان
علم التشريح
التنوع الإحيائي
البايلوجيا الخلوية
الأحياء المجهرية
البكتيريا
الفطريات
الطفيليات
الفايروسات
علم الأمراض
الاورام
الامراض الوراثية
الامراض المناعية
الامراض المدارية
اضطرابات الدورة الدموية
مواضيع عامة في علم الامراض
الحشرات
التقانة الإحيائية
مواضيع عامة في التقانة الإحيائية
التقنية الحيوية المكروبية
التقنية الحيوية والميكروبات
الفعاليات الحيوية
وراثة الاحياء المجهرية
تصنيف الاحياء المجهرية
الاحياء المجهرية في الطبيعة
أيض الاجهاد
التقنية الحيوية والبيئة
التقنية الحيوية والطب
التقنية الحيوية والزراعة
التقنية الحيوية والصناعة
التقنية الحيوية والطاقة
البحار والطحالب الصغيرة
عزل البروتين
هندسة الجينات
التقنية الحياتية النانوية
مفاهيم التقنية الحيوية النانوية
التراكيب النانوية والمجاهر المستخدمة في رؤيتها
تصنيع وتخليق المواد النانوية
تطبيقات التقنية النانوية والحيوية النانوية
الرقائق والمتحسسات الحيوية
المصفوفات المجهرية وحاسوب الدنا
اللقاحات
البيئة والتلوث
علم الأجنة
اعضاء التكاثر وتشكل الاعراس
الاخصاب
التشطر
العصيبة وتشكل الجسيدات
تشكل اللواحق الجنينية
تكون المعيدة وظهور الطبقات الجنينية
مقدمة لعلم الاجنة
الأحياء الجزيئي
مواضيع عامة في الاحياء الجزيئي
علم وظائف الأعضاء
الغدد
مواضيع عامة في الغدد
الغدد الصم و هرموناتها
الجسم تحت السريري
الغدة النخامية
الغدة الكظرية
الغدة التناسلية
الغدة الدرقية والجار الدرقية
الغدة البنكرياسية
الغدة الصنوبرية
مواضيع عامة في علم وظائف الاعضاء
الخلية الحيوانية
الجهاز العصبي
أعضاء الحس
الجهاز العضلي
السوائل الجسمية
الجهاز الدوري والليمف
الجهاز التنفسي
الجهاز الهضمي
الجهاز البولي
المضادات الميكروبية
مواضيع عامة في المضادات الميكروبية
مضادات البكتيريا
مضادات الفطريات
مضادات الطفيليات
مضادات الفايروسات
علم الخلية
الوراثة
الأحياء العامة
المناعة
التحليلات المرضية
الكيمياء الحيوية
مواضيع متنوعة أخرى
الانزيمات

Storing Genetic Information
 المؤلف:
AN INTRODUCTION TO PLANT BIOLOGY-1998
المؤلف:
AN INTRODUCTION TO PLANT BIOLOGY-1998
 المصدر:
JAMES D. MAUSETH
المصدر:
JAMES D. MAUSETH
 الجزء والصفحة:
الجزء والصفحة:
 29-10-2016
29-10-2016
 2889
2889




+
-
20
Storing Genetic Information
PROTECTING THE GENES
It is critically important that the information in DNA be stored accurately for a long time; if storage is not safe, the information produced by the DNA will be inaccurate and probably useless or even harmful. There are several ways in which DNA is kept relatively inert and safely stored.
1- DNA does not participate directly in protein synthesis. Instead, DNA produces a messenger molecule, messenger RNA (mRNA), which carries information from DNA to the site of protein synthesis. The mRNA, not DNA, is exposed to the numerous enzymes, substrates, activators, and controlling factors of protein synthesis (Fig. 1). If mRNA is damaged, it can be replaced with more copies of mRNA. Within a single cell, thousands of individual molecules of a particular enzyme may be needed; if the DNA itself had to direct the synthesis of each protein molecule, it would probably be damaged long before enough protein had been synthesized. But instead, DNA directs the production of several copies of mRNA, each of which directs the production of hundreds of protein molecules.
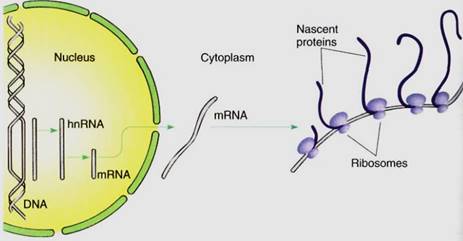
FIGURE 1:When a gene is active, its sequence of nucleotides guides the synthesis of "heterogeneous nuclear RNA," whose nucleotide sequence is complementary to that of the gene. The hnRNA is modified into messenger RNA, which is transported to the cytoplasm; it binds to ribosomes that translate (read) the nucleotide sequence in the mRNA and polymerize amino acids in the proper order, thus creating a protein. Ribosomes on the left have just started, so their proteins are still short; ribosomes on the right have read almost all the RNA, so their proteins are longer, almost complete.
2. Most DNA is stored in the nucleus, protected from the cytoplasm by the nuclear envelope. During interphase, the nuclear envelope forms the outer boundary of the nucleus. keeping most cytoplasmic components out and the proper nuclear substances in. The DNA of plastids and mitochondria are protected from cytosol enzymes by being located within plastids and mitochondria themselves.
3. Histone proteins hold most nuclear DNA in an inert, resistant form. Histones are a special class of proteins found in all organisms that have nuclei (plants, animals, fungi, algae, and protozoans). There are five types—HI, H2A, H2B, H3, and HA. The last four are among the most highly conserved proteins known; that is, the sequence of amino acids in the histones of one organism is virtually identical to the sequence in any other organism. For example, the H4 histone contains 103 amino acids, and its sequence in higher animals, such as cows, differs from its sequence in higher plants, such as peas, at only two sites (Fig. 2). Histone proteins are so essential that virtually any change in their amino acid sequence causes the organism to die or at least not reproduce.
Histones form aggregates and DNA wraps around them, forming a spherical structure called a nucleosome. Histone H1 then binds nucleosomes into a tightly coiled configuration. In this mode the DNA/protein structure—chromatin—is so dense that enzymes cannot penetrate it and DNA is relatively inert: Even if it is exposed directly to DNA-digesting enzymes, called DNases (also written as DNAases), histone-bound DNA is not extensively damaged. However, chromatin is still sensitive to regulatory molecules and can be unpacked in preparation for synthesis of mRNA or for replication of DNA during the S phase of the cell cycle.

FIGURE 2:The nucleotide sequence for the gene for histone H4 in wheat is presented in the top row of each set of lines. In the second row is the sequence for the same gene for a different type of wheat. Where the two genes are identical, only a dash appears for the second gene. The portion of the gene that codes for protein begins in the fifth line (labeled +1), and the amino acid sequence—the primary structure of the protein—is given in the third row of each set of lines. Wherever a mutation has caused the second gene to code for an amino acid different from the first gene, that amino acid is given in the fourth row. Although 18 mutations have occurred, the resulting amino acid sequence is unchanged except at one site (most of these mutations have no effect because the genetic code is redundant—see later in chapter). The noncoding regions of the gene—from the beginning to +1, and from +309 to the end—are not highly conserved, and the two genes differ greatly in these sites. (Sequence data obtained by T. Tabata and M. Iwabuchi)
THE GENETIC CODE
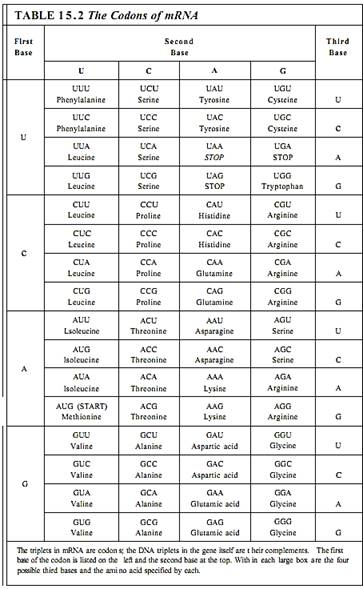
Twenty types of amino acids are used in synthesizing proteins, but only four different nucleotides are present in DNA or mRNA; consequently, it is not possible for one nucleotide alone to specify one amino acid, because 16 amino acids would be left without nucleotides to code for them. Similarly, nucleotides cannot be used simply in pairs of two, such as AU for isoleucine or CC for proline, because there are only 16 possible pairs. It is necessary for nucleotides to be read and used in groups of three; 64 possible triplets, known as codons, can be made using four nucleotides. Table 15.2 shows which amino acid is coded by each codon.
With 64 possible triplets, a surplus of 44 codons remains after each amino acid is paired with a codon. Three of the codons—UAA, UAG, and UGA—are stop codons; they signal that the ribosome should stop protein synthesis. The codon AUG is the start codon that signals the point in mRNA where protein synthesis should begin. The extra 40 codons also code for amino acids, so most amino acids have two or more codons. For example, both UUU and UUC code for phenylalanine, and CAU and CAC code for histidine. Because multiple codons exist for most amino acids, the genetic code is said to be degenerate. Degeneracy further protects DNA: A mutation in DNA might change a codon in mRNA from UUU to UUC for example, but because both code for phenylalanine, the same protein is produced before and after this particular mutation.
The genetic code is almost perfectly universal; all organisms and genetic systems but one share the genetic code shown in Table 15.2. Viruses, bacteria, fungi, animals, and plants all use the same codons to specify particular amino acids, and the same is true £r plastid DNA. Only in mitochondria are several codons changed. This almost universal commonality of the genetic code is one of the strongest pieces of evidence that life arose only once on Earth and that all living organisms have evolved from one ancestral organism.
THE STRUCTURE OF GENES
Most genes, up to 90% in any cell, are quiescent most of the time and are activated and read only when the cell needs the particular enzymes they code for. Each gene must have a structure that allows controlling substances to recognize the gene, bind to it, and activate it at the proper time.
Genes are composed of a structural region that actually codes for the amino acid sequence, and a promoter, a controlling region involved in regulating the synthesis of mRNA from the structural region (Fig. 3). The promoter is located "upstream" from the structural region, that is, to the 5' side. It varies in length from gene to gene but can be several hundred nucleotides long. Certain regions are particularly important; one, called the TATA box, is a short sequence about six to eight base pairs long rich in A and T. If the TA3A box is damaged by either mutation or experimental treatment, the RNA-synthesizing enzyme RNA polymerase II does not bind well. Most eukaryotic genes have other promoter sequences called enhancer elements located even farther upstream, as many as several hundred base pairs away from the structural region of the gene. It is hypothesized that when a hormone alters cell metabolism, it does so by producing intracellular chemical messengers that activate genes either by binding directly with the promoter region or by binding with proteins that then interact with the promoter. After activating agents have bound to the promoter, RNA polymerase II can attach.
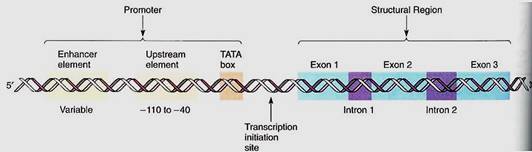
FIGURE 3:A gene is always written with the 5' end, and thus the promoter, on the left. Nucleotides are numbered beginning at the left boundary of the structural region; nucleotides to the left of this are given negative numbers and are said to be upstream. Because DNA is double-stranded, its length is measured as the number of nucleotide pairs or base pairs, whereas RNA, being single-stranded, is measured as the number of nucleotides or bases. The decision to speak of nucleotides versus bases is just personal choice.
Once RNA polymerase II binds to the promoter, it migrates downstream (toward the 3' end of the DNA strand) toward the structural region. However, it does not create any RNA until it is about 20 to 30 nucleotides below the TATA box. The RNA polymerase might be expected to search for the DNA equivalent of the AUG start codon of mRNA, but that is not the case. If some of the DNA is artificially removed between the TATA box and the normal start site, the RNA polymerase begins synthesizing RNA farther downstream than normal.
The structural portion of genes contains two distinct types of regions: exons and introns. Exons are sequences of nucleotides whose codons are eventually expressed (exon, expressed) as sequences of amino acids in proteins, and introns are sequences of nucleotides that are not expressed, but instead intervene between exons (Figs. 3 and 4). Several plant genes have just two or three introns: the gene for RuBP carboxylase and the genes for the storage proteins glycinin and phaseolin of legume cotyledons. The gene that codes for the protein portion of phytochrome has five introns, one of which is 1500 base pairs long. Genes with 25 introns occur, as do genes with no introns.
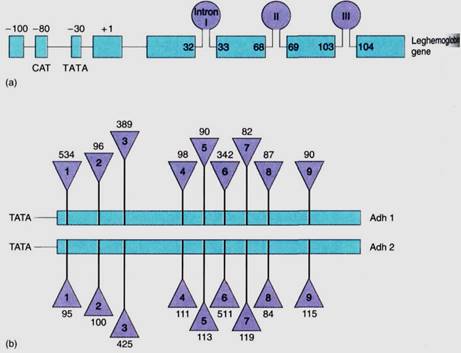
FIGURE 4:Two ways of illustrating introns and exons in maps of genes. (a) The gene for leghemoglobin in legumes has three introns: Intron I occurs between bases 32 and 33 of the finished mRNA; intron II between bases 68 and 69, and so on. (After Brown et al, J. Moleuler Evolution 21:19-32, 1984) (b) Two genes in corn produce two similar enzymes, both called alcohol dehydrogenase and distinguished as Adhl and Adh2. The numbers above and below the triangles indicate the number of bases present in each intron. The two genes are similar, having nine introns located at the same positions; corresponding exons in Adhl and Adh2 are the same length, but corresponding introns may be quite different. Intron 1 is 534 bases long in Adhl but only 95 bases long in Adh2. (After Llewellyn et at, Molecular Form and Function of the Plant Genome. Edited by Vloten Doting et al. New York, Plenum Press, 1985)
TRANSCRIPTION OF GENES
After RNA polymerase binds and encounters the start signal, it begins actually creating RNA, a process called transcription. The two strands of DNA separate from each other over a short distance, and free ribonucleotides diffuse to the region (Fig. 5). If a ribonucleotide containing cytosine approaches a DNA nucleotide that contains guanine, the two form three hydrogen-bonds and remain together, at least temporarily. Wherever DNA contains T, a free A can form two hydrogen-bonds to it; similarly, free U forms two hydrogen-bonds with A in DNA, and so on with G and C. RNA polymerase binds the free ribonucleotide, holds it, and catalyzes the formation of a covalent bond, forming RNA.
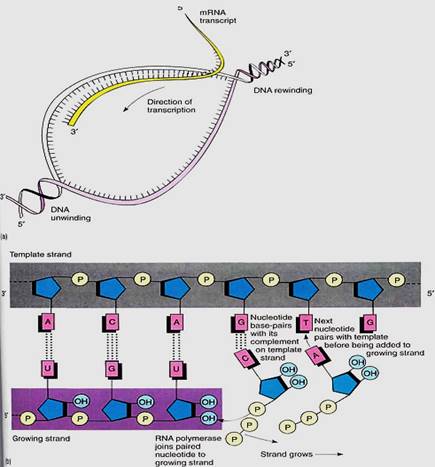
FIGURE 5:When a gene is turned on, the DNA double helix separates over a short region (a); free ribonucleotides can now diffuse in and pair with the region of temporarily single-stranded DNA (b). The formation of two or three hydrogen-bonds between the DNA deoxyribonucleotides and the free ribonucleotides allows the DNA sequence to control the sequence of the RNA being formed.
As each covalent bond is formed, two high-energy phosphate-bonding orbitals are broken, so polymerization is a highly exergonic process that cannot be easily reversed.
Transcription proceeds rapidly, incorporating about 30 ribonucleotides per second, with the DNA double helix unwinding ahead of the moving enzyme. Once RNA polymerase moves off the promoter/initiation site, a new molecule of RNA polymerase binds and begins synthesizing another molecule of RNA (Fig. 6). Whereas two molecules of DNA wrap around each other into a double helix, RNA/DNA duplexes do not; the RNA polymer that emerges from RNA polymerase releases from the DNA.
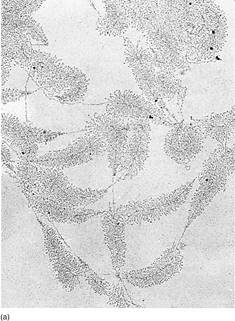
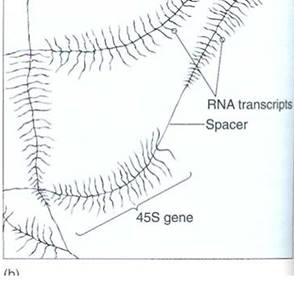
FIGURE 6:DNA can be carefully extracted from a nucleus, allowed to spread out, and then prepared fir J examination in an electron microscope (a). These are ribosomal genes being transcribed into long RNAs that will later be cut into three separate rRNAs. (Courtesy of O. L. Miller, University Virginia) The diagram (b) explains each type of line.
RNA polymerase continues to act until it encounters a transcription stop signal in the DNA. The stop signal of several genes consists of two parts. The first is a short series of DNA nucleotides that arc self-complementary; that is, the RNA transcribed from them can double back on itself and hydrogen bond to another part of itself. This results in a small kink, a hairpin loop that is believed to affect RNA polymerase. Just downstream of this region of DNA is a long series of adenines. Various protein factors also are involved; in their absence RNA polymerase sometimes continues transcribing, reading the next region of DNA as if it were also part of the gene.
RNA polymerase transcribes both introns and exons into a large molecule of hnNRA (heterogeneous nuclear RNA) that is rapidly modified by nuclear enzymes. Introns are recognized, cut out, and degraded back to free ribonucleotides. Exons are spliced together, resulting in an RNA molecule, all of which codes for amino acids. All RNA destined to become mRNA is somehow recognized by an enzyme that binds to it and attaches a series of adenosine ribonucleotides on its 3' end, forming a poly(A) tail about 200 bases long. the only exception being the mRNAs for histone proteins (Fig. 7). Another step in message processing involves changing the first nucleotide into 7-methyl guanosine. Ultimately a completed mRNA is produced and transported from nucleus to cytoplasm.
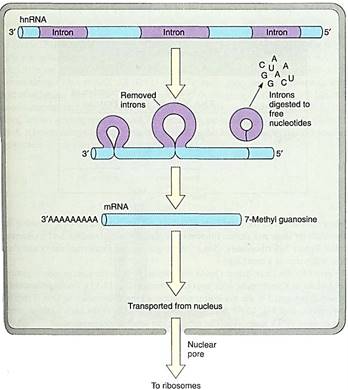
FIGURE 7:The primary transcript, hnRNA, has its introns cleaved out and the exons spliced together; the introns are depolymerized back to free nucleotides. An enzyme adds up to 200 adenosine ribonucleotides to the end of the RNA; these are not coded by thymidines in the DNA. The first nucleotide at the 5' end is converted to 7-methyl guanosine.
 الاكثر قراءة في مواضيع عامة في علم النبات
الاكثر قراءة في مواضيع عامة في علم النبات
 اخر الاخبار
اخر الاخبار
اخبار العتبة العباسية المقدسة

الآخبار الصحية


مواضيع ذات صلة
 قسم الشؤون الفكرية يصدر كتاباً يوثق تاريخ السدانة في العتبة العباسية المقدسة
قسم الشؤون الفكرية يصدر كتاباً يوثق تاريخ السدانة في العتبة العباسية المقدسة "المهمة".. إصدار قصصي يوثّق القصص الفائزة في مسابقة فتوى الدفاع المقدسة للقصة القصيرة
"المهمة".. إصدار قصصي يوثّق القصص الفائزة في مسابقة فتوى الدفاع المقدسة للقصة القصيرة (نوافذ).. إصدار أدبي يوثق القصص الفائزة في مسابقة الإمام العسكري (عليه السلام)
(نوافذ).. إصدار أدبي يوثق القصص الفائزة في مسابقة الإمام العسكري (عليه السلام)